splunk
![]()
Methodology
Testing Objective and Approach
The methodology of the testing adheres to the following overarching statement:
To Benchmark the Sunlight.io Virtualization platform against comparable AWS environments with particular focus on storage performance (IOPS) to ascertain if there is a significant advantage for Splunk workloads.
The target focus of the testing is to evaluate running Splunk workloads in an AWS hosted environment and to implement comparable environments hosted on AWS EC2 instances, vs Sunlight instances hosted on AWS “Bare Metal” z1d instance families.
Given that the underlying hardware compute infrastructure is identical, it can be presumed that resources such as CPU/Memory will be identical between environments. The focus for comparison is the storage advantages (if any) that Sunlight instances provide over EC2 EBS volumes – both GP2 SSD and provisioned IOPS volumes.
Hypothesis
Due to the focus on the IOPS performance the hypothesis under test is as follows:
Given the greater bare metal performance achieved by the Sunlight.io HCI stack, Splunk will be able to take advantage of greater storage IOPs performance compared to an identically sized AWS virtual machine.
The tests carried out will focus on the following metrics in order to test the upper limits of the IOPs on the machines.
| Metric | Description |
|---|---|
| IOPs vs MB/s data | Test the IOPs performance in both the AWS and Sunlight virtualisation against incoming data |
| IOPS vs searches | Test the IOPs performance of the Indexers against a number of searches |
Event Generation
In order to generate events, typical of those seen in real world Splunk environments, the Splunk event generator app – SA_Eventgen will be used.
A sample_data app was configured to send samples of the following types of logs:
- Bluecoat access
- Mcafee EPO
- Sophos threat (2 sourcetypes)
Each type of log generation has an interval in seconds and a count. This determines how many logs are generated. For example for Bluecoat:
[http_log.6.5.bluecoat]
interval = 1
earliest = -10m
latest = now
count = 1000
sourcetype=bluecoat:proxysg:access:file
disabled = 0
index = bluecoat
outputMode = s2s
splunkHost = {{ indexer_ip}}
splnukPort = 9997
Each event gen heavy forwarder will be optimised to send as much data as possible. To increase the data sent to Splunk further we will scale horizontally and install more Heavy Forwarders.
Search Load Generation
It is common for Splunk environments to run the Splunk Common Information Model (CIM) application to normalise event data. The CIM invokes a number of background searches to populate datamodels for use in other Splunk applications. The CIM application will be installed and configured to populate (accelerate) the relevant CIM data models. This provides a base 'background' search load.
In addition to the CIM DM acceleration searches, a suite of scheduled searches will be used and configured such that they are constantly executing to simulate a number of concurrent users. These searches will be designed to execute for a longer period of time.
Jobs will run in several of the following configurations:
- 1 minute bounded – Jobs will run for 55 seconds, then terminate and restart each minute
- 2 minute bounded – Jobs will run for 110 seconds, then terminate and restart every 2 minutes
- Unbounded – these jobs will execute for as long as the results take to complete. They will be scheduled to execute every 5 minutes, but the next run(s) will skip if the previous search has not completed.
The searches will comprise a number of the following types
- Inefficient “wildcard prefix” searches e.g “*something” (see Appendix 4 for more information)
- All Index, All Time searches
- All Index, String searches e.g. “some string”
- All Index, Key=value searches
- Specified index statistical searches “stats count”
Whilst it is not possible to simulate a truly representative simulation of real-world user concurrency, these searches will apply a load to indexers that tests both CPU and storage capabilities of the indexers.
In all cases, the target is to achieve an average search concurrency of approx. 20 searches at all times to maximise the use of available resources; 20 is derived from the number of cores available on the SH (16) X searches per core (1) + base searches (6) = 22 total, with a 10% search availability remaining available within the deployment.
Splunk Deployment
Ansible scripts will be written to deploy the base Splunk servers and their configuration. The configuration will be created using Splunk’s base configuration apps. These scripts should be able to both deploy the environment and push out configuration changes. Test configurations and details are provided in Appendix 1.
Test Environments
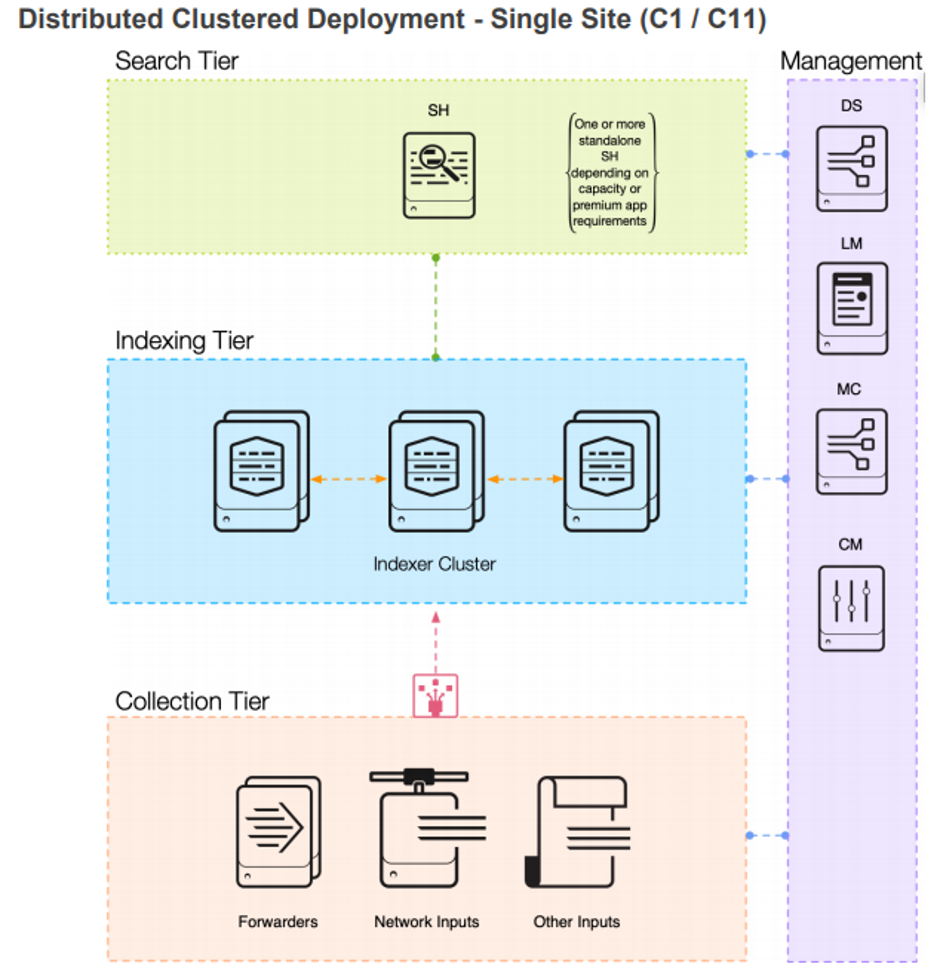
The testing was carried out on two test environments. The first one following the D1 (see Appendix 2) distributed Validated Architecture and the second environment following the C1 (see Appendix 3) clustered validated architecture.
Test Environment 1
The purpose of these tests is to more accurately benchmark the performance of AWS vs SL when the compute resources are equal between the environments.
It is hypothesised that since both environments were displaying similar CPU usage metrics, whilst still comparatively low IOP values, CPU contention could be contributing to the reduced IOPS Sunlight advised that they thought achievable.
For this reason, the indexer CPU core were increased to 36, with 60GB of memory.
The environments would be deployed with identical hardware specification and the same baseline was established, that being:
- Splunk CIM data model accelerations enabled
- The suite of background scheduled searches were running
- A suitable amount of data was indexed spanning a period of 12 hours to conduct the test searches against. 20:00 – 08:00hrs
- Buckets were sized at 350MB
- CPU usage across both environments was ~85%
- Memory consumption was minimal ~15%
The same searches will be run against both environments and the number of results will be recorded along with the time to execute the search. (Short running searches were run several times and average times recorded).
The searches will also run with the indexer receiving events at a rate of approx. 20Mb/s and repeated with indexing quiesced.
In all cases the test suite of scheduled searches and datamodel accelerations were left running to simulate the background search load.
Test Environment - AWS EC2 - Splunk Architecture D1
| Tier | VM Name | Qty | AWS Instance Type | Number of Cores | RAM (GB) | Disk Size (GB) |
|---|---|---|---|---|---|---|
| Search | Search Head | 1 | c4.4xlarge | 16 | 30 | 100 |
| Indexing | Indexer | 1 | c4.8xlarge | 36 | 60 | 800 |
| Forwarding | Heavy Forwarder | 4 | c4.xlarge | 4 | 7.5 | 50 |
| Management | Management | 1 | c4.xlarge | 4 | 7.5 | 50 |
Test Environment - Sunlight on AWS Bare Metal - Splunk Architecture D1
| Tier | VM Name | Qty | Sunlight cluster node index | Number of Cores | RAM (GB) | Disk Size (GB) |
|---|---|---|---|---|---|---|
| Search | Search Head | 1 | 1 | 16 | 30 | 100 |
| Indexing | Indexer | 1 | 1 | 36 | 60 | 800 |
| Forwarding | Heavy Forwarder | 4 | 2 | 4 | 7.5 | 50 |
| Management | Management | 1 | 2 | 4 | 7.5 | 50 |
Test Environment 2
The second test environment aimed to evaluate the impact of implementing a Clustered Indexer to assess the search improvements it could deliver. The environment was deployed and the same baseline was established as in test environment 1.
Test Environment - Sunlight on AWS Bare Metal - Splunk Architecture C1
| Tier | VM Name | Qty | Sunlight cluster node index | Number of Cores | RAM (GB) | Disk Size (GB) |
|---|---|---|---|---|---|---|
| Search | Search Head | 1 | 2 | 16 | 16 | 100 |
| Indexing | Indexer | 3 | 1(x2) 2(x1) | 12 | 12 | 800 |
| Forwarding | Heavy Forwarder | 4 | 1(x2) 2(x2) | 4 | 7.5 | 50 |
| Management | Management | 1 | 2 | 4 | 7.5 | 50 |
| Cluster Master | Cluster Master | 1 | 1 | 4 | 7.5 | 50 |
Results
Test Environment 1 Results
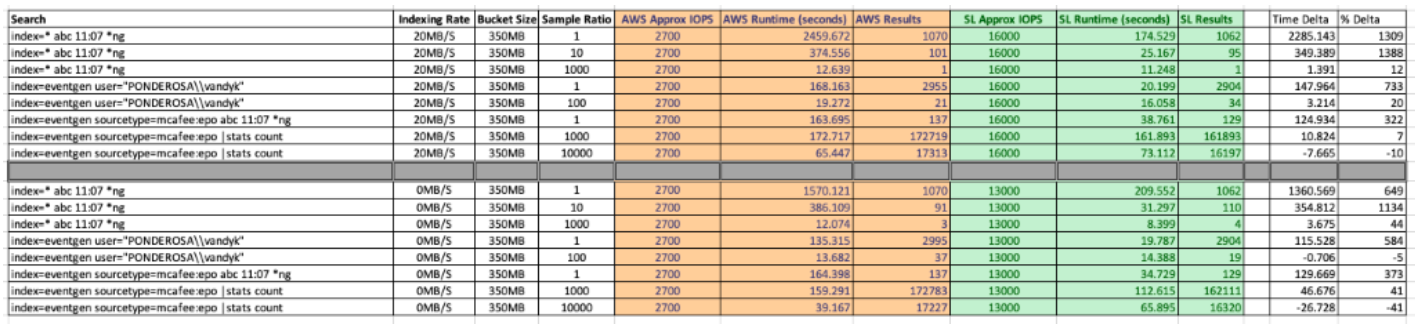
IOPs vs 20MB/s data
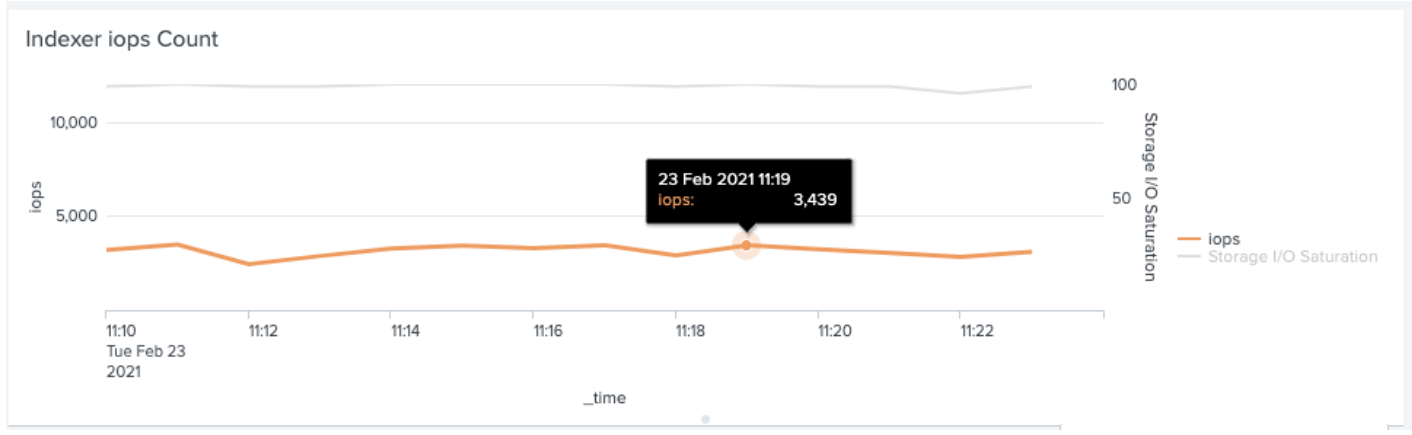
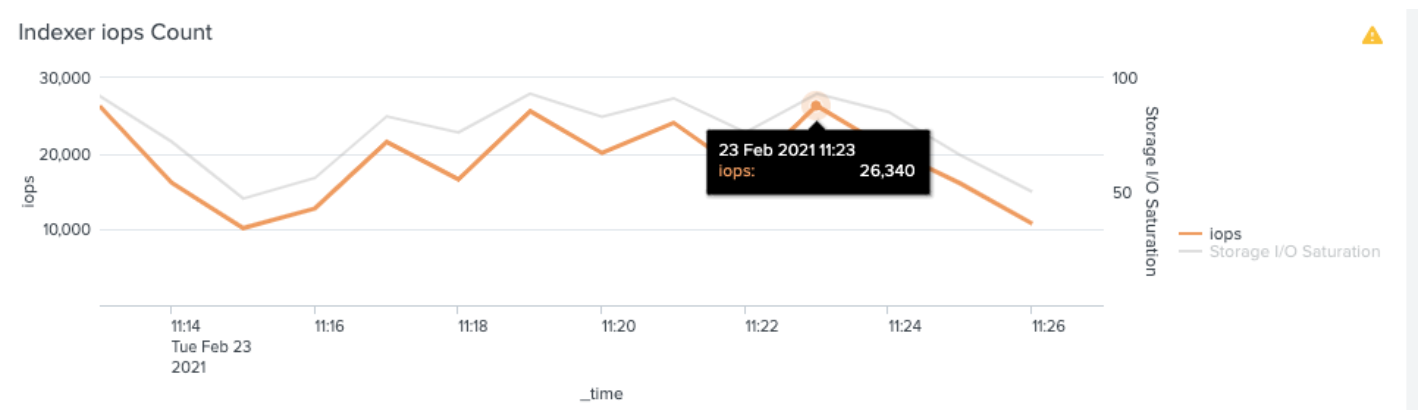
In terms of quantifying these results these can be summarized as follows:
Splunk on Sunlight Performance Advantages (Heavy Search Load - Single Indexer, Single Storage Device)
| Number of Cores | AWS EC2 Indexer IOPs (peak) | Sunlight Indexer IOPs (peak) | Difference Sustained (peak) | IO Advantage (peak) |
|---|---|---|---|---|
| 16 | 3,000 (3,500) | 8,500 (10,000) | 5,500 (6,500) | 183% (185%) |
| 36 | 3,000 (3,600) | 19,000 (27,000) | 16,000 (23,400) | 533% (650%) |
IOPS vs concurrent searches
After enabling the suite of saved searches on both environments there is a significant increase in IOPS consumption. Notable however is that IO saturation is significantly higher on AWS EC2.
AWS IOPS & Saturation (Search Load, little data)
Sunlight IOPS & Saturation (Search Load, little data)
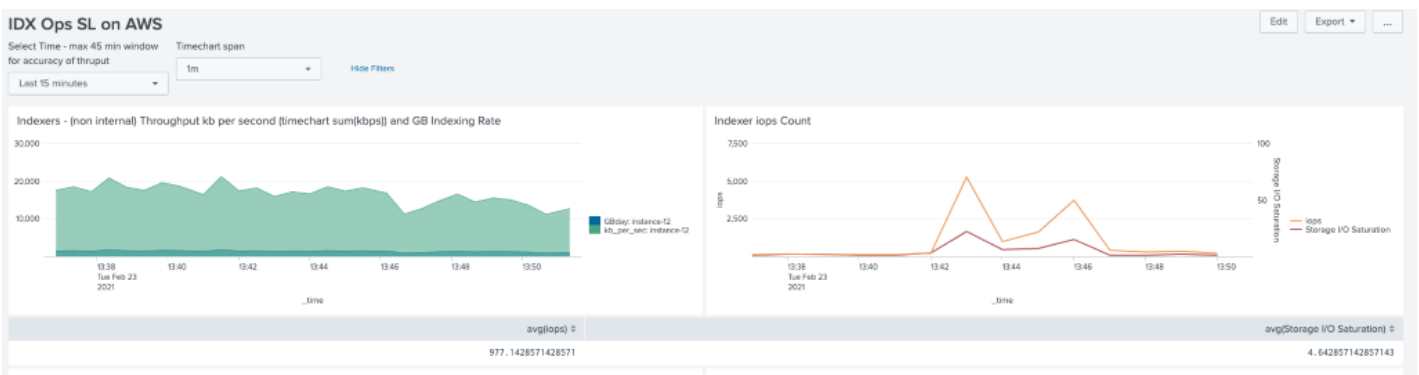
AWS IOPS & Saturation (Search Load, 12 hour dataset)
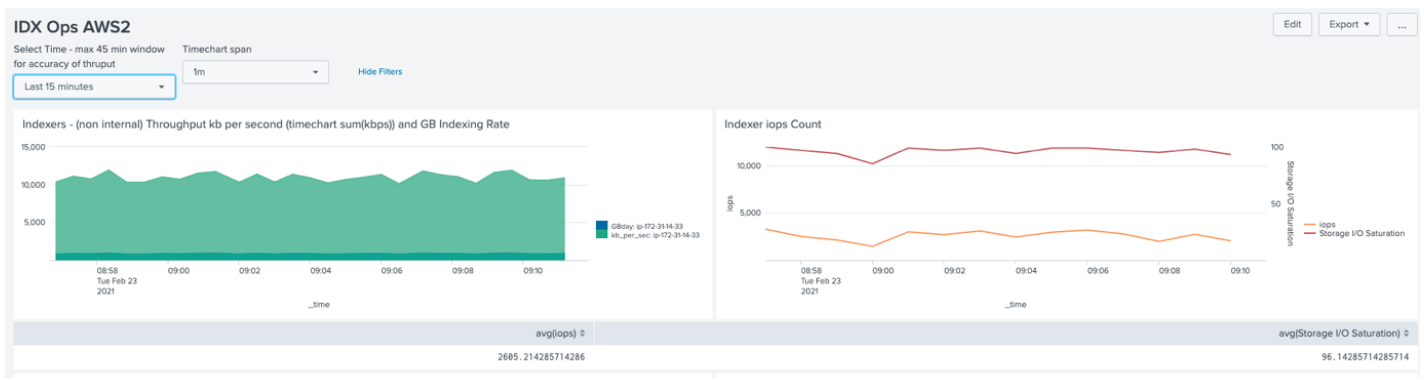
Sunlight IOPS & Saturation (Search Load, 12 hour dataset)
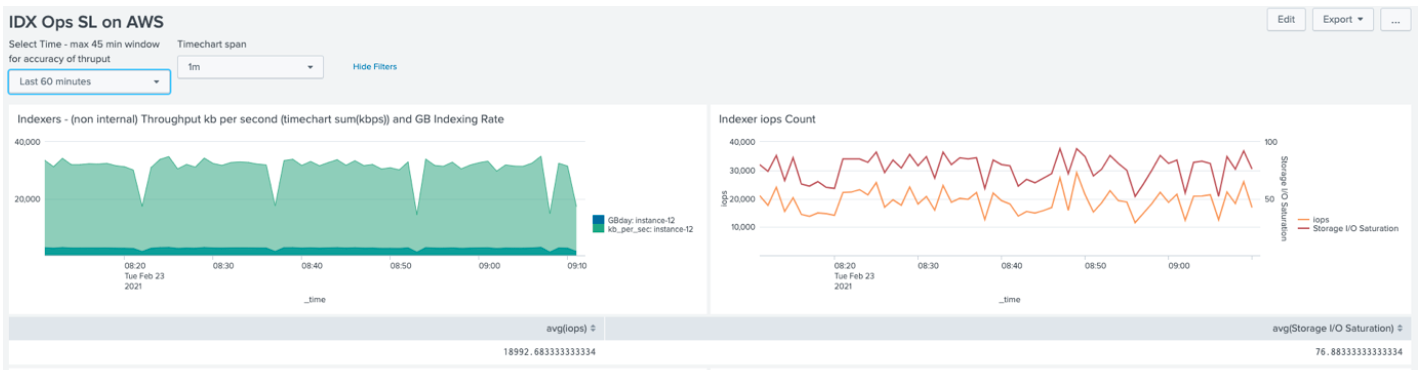
Test Environment 2 Results
IOPs vs 18MB/s data and concurrent searches
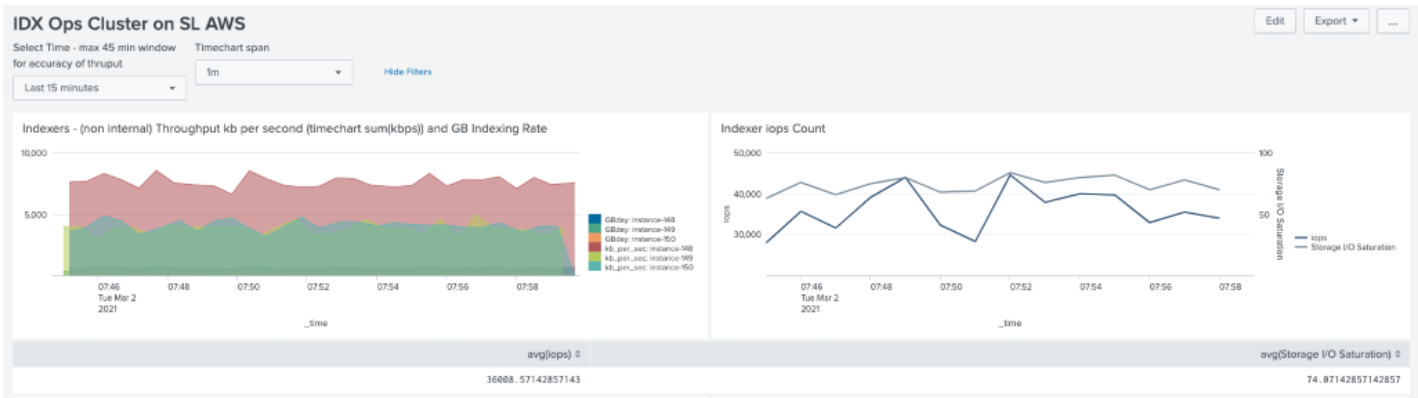
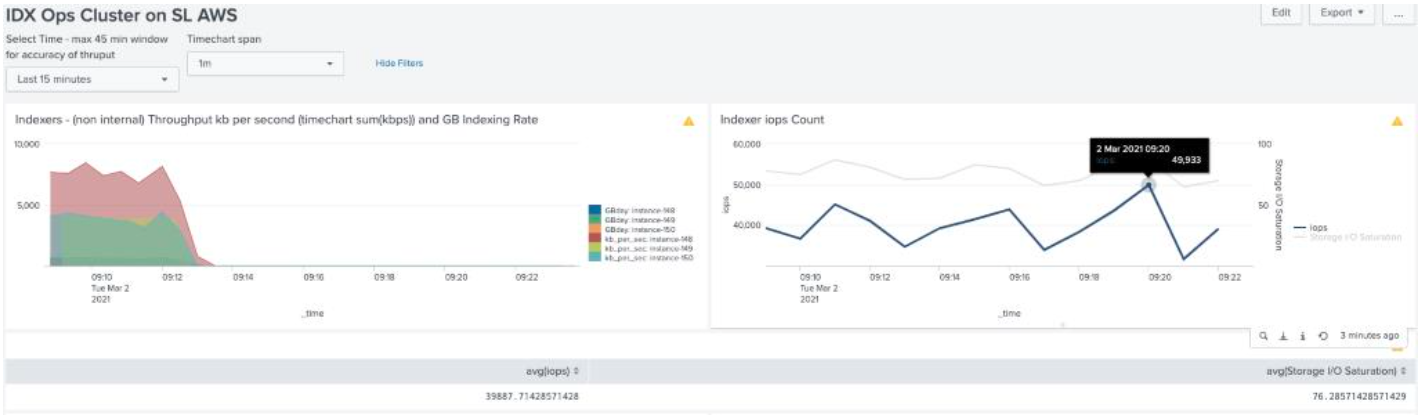
IOPs vs concurrent searches
Discussion
Test Environment 1 Discussion
AWS Max sustained IOPS around ~3000 (peaked at 3600) At this level IO Saturation was reported as near/at 100%.
It is clear from this batch of testing that the increased CPU count does not provide any uplift to the available IOPs on an AWS EBS System. This matches expectations as the EBS volume is IOP limited.
The Sunlight deployment however did benefit from the increased core count. By enabling 36 cores it was demonstrated that Splunk would consume a sustained ~19,000 IOPS (peaked at 27,000) with high saturation levels in excess of 75%.
Whilst there may still be some additional performance gains obtained with even higher core counts the difference in IO throughput is substantial compared with AWS.
With a background search load applied, the baseline IOPS varies greatly between the two environments.
Whilst indexing the Sunlight environment was operating on average around 16,000 IOPS which reduced when indexing was stopped by approx. 3000 IOPS to around 13,000. This matches observations elsewhere during testing, indicating that a single indexer under heavy ingest load can consume around 3000 IOPS for index operations. Notable, however, is that the background IOPS level on the AWS environment was not overtly affected by indexing load.
The logical reasoning for this is that an AWS instance with an 800GB GP2 volume is IOP limited around 3000 IOPS. Since these tests indicate that the AWS instance is consistently hitting the hardware limit of the platform, the reduction in indexing load is masked by the background search impact.
Splunk will prioritize indexing operations over search, so it follows that on an IOP limited instance the contended system will not deliver as expedient search results.
Search performance on the Sunlight environment was largely unaffected by the indexing rate – there being sufficient IOP capacity spare on the system.
The AWS environment however did return faster results with indexing paused (benchmarked against itself) demonstrating that this allows search to consume the IOPS previously used for indexing.
Long running “dense” searches on the SL environment display the greater speed efficiency over shorter or sampled search jobs. Whilst dense searches place a lower demand on high IO throughput (as measured against sparse/sampled tasks) they require a consistent read performance to filter results. Dense searches also consume more compute resources (CPU/Mem) with which to collate/filter data.
Sampled searches typically require more IO operations as these quickly sample results across many buckets and quickly traverse the file system. In both environments sampled searches execute faster, with the performance delta closing between the two environments the higher the sample rate.
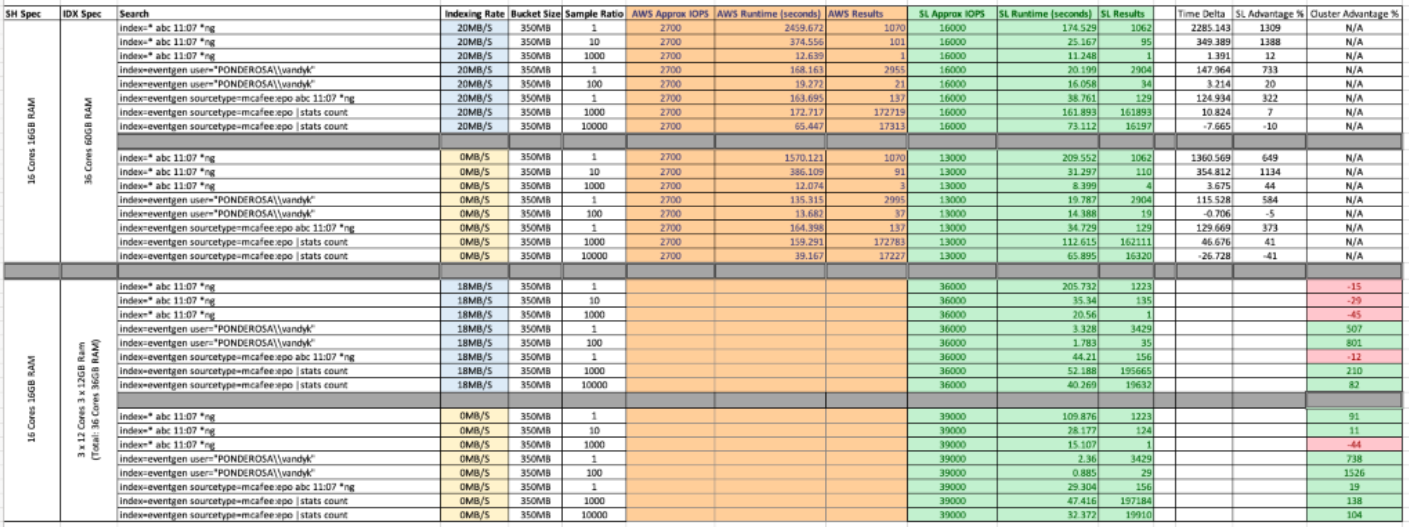
The results table (see figure 3), highlights the huge variations in search duration, but does paint the picture that in all of the scenarios tested, there are efficiencies with the SL environment ranging from single indexer improvements ranging ~10% - ~1400%.
Test Environment 2 Discussion
During the first set of tests (indexing at 18mb/s) average cluster IOPS were 36k with storage saturation around 75%. One indexer (shown in red in figure "IOPs vs 18MB/s data and concurrent searches") was handling 50% more ingest than others. Before testing started a data rebalance was triggered to normalize the bucket distribution between all peers.
The tests highlight that ‘bad searches' (i.e. those which prefix search teams with a “*”) execute faster against a single indexing node, showing efficiency differences of between 12-45% in favour of single indexer dispatch. However, all other searches execute significantly faster against the Map/Reduce Splunk search architecture delivering enhancements of between 11-1500%. This is because efficient searches are able to be split between all search peers and run in parallel by each indexer against (approx.) 1/3 of the data. For the second suite of tests, as per test 2, indexing was paused (see figure "IOPs vs concurrent searches").
Notable in this scenario is that IOPs increased marginally – peaking at just shy of 50k. This also delivered marginal performance gains vs when indexing. This likely indicates that CPU contention could be an issue at high indexing rates.
Bad searches (laden with wildcards) are discouraged in Splunk because they limit the Map/Reduce efficiencies within the architecture. Concise well executed searches are significantly more performant in clustered environments due to the parallelization that can be applied to them. Whilst these results have not been benchmarked against a comparable AWS environment, we know that AWS indexers with GP2 volumes would be limited at ~3000-3500 IOPs, so the maximum cluster IOPs we would anticipate realizing would be around 10k - several orders below what SL is achieving.
To facilitate a comparable architecture for testing, the AWS environment would need each indexer to have provisioned IOP volumes providing at least 15,000 – 20,000 IOPS.
Conclusion
Splunk was able to take advantage of up to 30,000 SL IOPS on a single instance, or 50,000 IOPS clustered.
- Sunlight delivers a 10x IOPs enhancement over a single node indexer
- Sunlight delivers a 5x IOPs enhancement over a 3-node indexer cluster
This I/O increase translated into a 12-45% increase in search speed on a single indexer dispatch and an 11-1500% increase in search speed when using the Map/Reduce search architecture of the cluster. The larger increases in search speed occurred when carrying out longer historical searches. Worthy of note is that Splunk advises a target IOP requirement of 800 base IOPS plus 400 IOPS per parallel ingestion pipeline, in all of these tests we were significantly outperforming these requirements.
Appendix
Appendix 1 – Configuration Details
A sample_data app has been created to send various amounts of logs with the SA-Eventgen app of the following sourcetypes:
- Bluecoat access
- Mcafee EPO
- Sophos threat (2 sourcetypes)
In order to log the performance metrics from the testing TA_Splunk_Nix and CollectD were configured.
The app mapping for the first test and second test environment as follows:
| Tier | Apps |
|---|---|
| Search Head | sunlight_all_forwarder_outputs sunlight_full_license_server sunlight_all_indexes Splunk_TA_bluecoat-proxsg Splunk_TA_mcafee Splunk_TA_sophos Splunk_TA_nix |
| Indexers | sunlight_full_license_server sunlight_all_indexes sunlight_all_indexer_base Splunk_TA_nix Splunk_TA_bluecoat-proxsg Splunk_TA_mcafee Splunk_TA_sophos CollectD stats |
| Forwarding Hosts | sunlight_full_license_server sunlight_all_forwarder_outputs SA-Eventgen sample_data |
| Management | sunlight_all_forwarder_outputs |
The second test environment introduced cluster configuration and the need for a cluster master. See appendix 2 and 3 for the Splunk Validated Architectures that were followed.
Appendix 2 – Splunk D1 Deployment
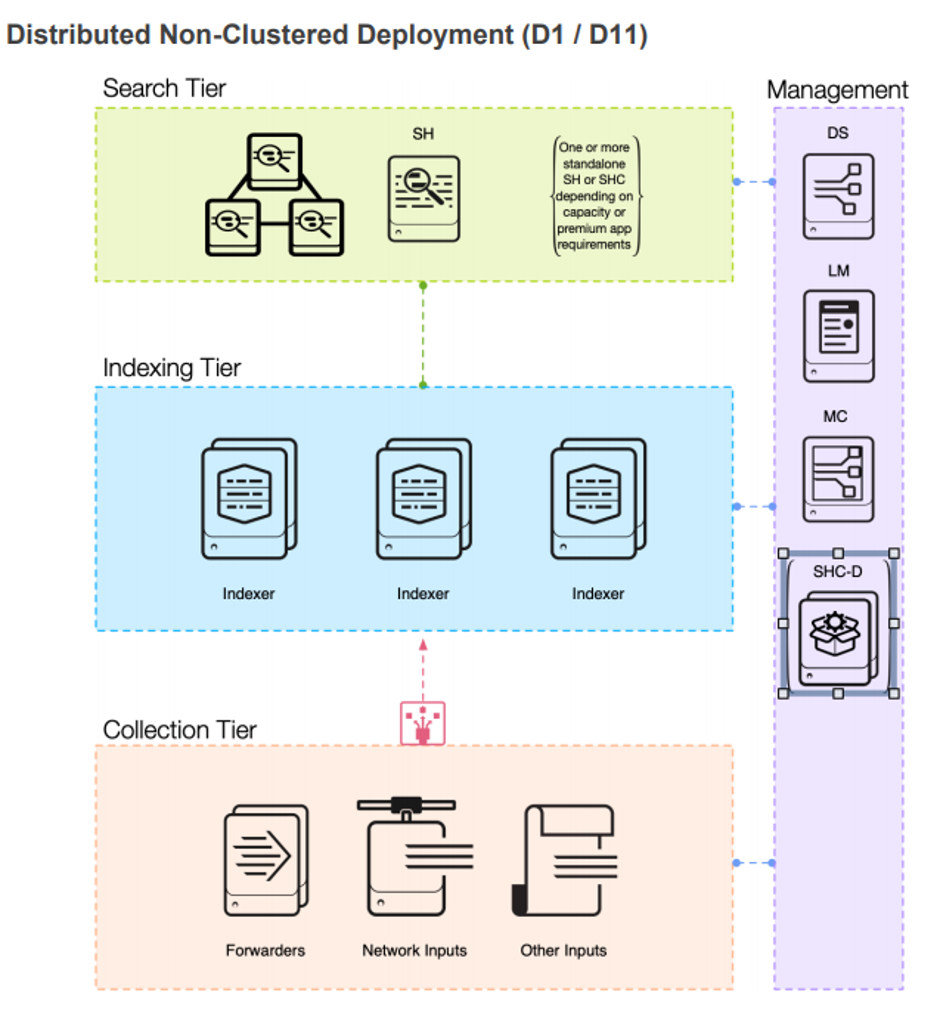
Appendix 3 – Splunk C1 Deployment
Appendix 4 – Additional Information
Splunk searches achieve efficiency by being as specific as possible as early as possible. Defining key metadata such as _time, index, host, source and sourcetype immediately means Splunk can ignore any data bucket that does not contain this metadata or timeframe completely. This significantly reduces the search time. With that in mind searches that heavily impact Splunk are as follows:
- all time searches that do not limit the time range at all.
- Index=* searches, searching across all indexes.
- *10.1.1.1 leading wildcards which require the search head to check every string
- Using centralized streaming commands early in the search which forces the whole search onto that individual search head. Commands such as tail, transaction, eventstats, streamstats.
- Using transforming commands early need to see all events/results rows. Commands such as append, chart, join, stats, table, timechart, top.
- Using real time searches.