Apache Hadoop Benchmarking

Application description
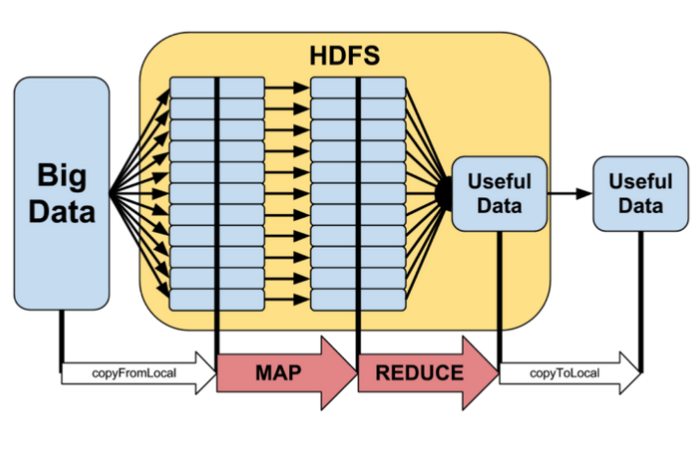
The Apache Hadoop project provides an open source framework for enabling massively distributed compute scaling both for computational and data storage scale. Hadoop clusters of nodes are built on top of the Hadoop Distributed FileSystem (HDFS) to provide localised access to shared data without impacting the overall locking and serialisation of the complete dataset. In this manner, local storage and CPU performance is an important factor in scaling overall system performance. Specifically, It provides a software framework for distributed storage and the processing of big data using the MapReduce. In a multi-node hadoop cluster, all the essential daemons are up and run on different hosts. A multi-node hadoop cluster setup has a master-slave architecture where in one machine acts as a master that runs the NameNode daemon while the other machines acts as slave or worker nodes to run other hadoop daemons.
Infrastructure Environment tested
The Apache Hadoop multi-node cluster application has been tested on the following:
| Host OS | Kernel Version | Multi-Queue Block |
|---|---|---|
| CentOS 7 | 3.10.0-862.14.4.el7.x86_64 | NO |
| CentOS 7 | 5.13.4-1.el7.elrepo.x86_64 | YES |
| CentOS 8.3 | 4.18.0-240.1.1.el8_3.x86_64 | NO |
| CentOS 8.3 | 5.13.4-1.el8.elrepo.x86_64 | YES |
| Resource | Value |
|---|---|
| Package manager | yum |
| Application version | 1.2.1 |
| Environments tested | XeonD Sunlight r5.2xlarge vs Bobcat Peak Sunlight r5.2xlarge |
| Flavour | Cores | Memory | Storage |
|---|---|---|---|
| r5.2xlarge | 6 | 4G | 200G |
Configuration and Setup description
Test data sizes are 100G per file, total 800 GB. Benchmark tested is the built-in TestDFSIO hadoop stress test utility.
| Resource | Value |
|---|---|
| Approx Package installation time | < 5 mins |
| Approx test execution time | ~ 8 mins |
/bin/hadoop jar /usr/share/hadoop/hadoop-test-1.2.1.jar TestDFSIO -write -nrFiles 8 -fileSize 12800
/bin/hadoop jar /usr/share/hadoop/hadoop-test-1.2.1.jar TestDFSIO -read -nrFiles 8 -fileSize 12800
/bin/hadoop jar /usr/share/hadoop/hadoop-test-1.2.1.jar TestDFSIO -clean
You can find this hadoop application available as recipe from the SIM marketplace.
Data Results Table
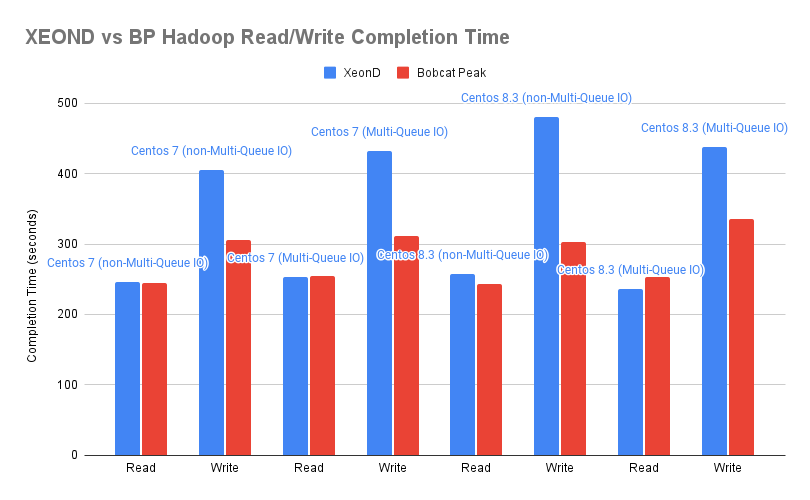
Test completion time
| Flavour | Server Enviroment | Host OS | Multi-Queue Block | Write | Read | Combined RW (50:50) |
|---|---|---|---|---|---|---|
| Sunlight r5.2xlarge | Xeond | CentOS 7 | Disabled | 405.497 | 246.516 | 326.006 |
| Sunlight r5.2xlarge | BP | CentOS 7 | Disabled | 305.375 | 244.323 | 247.849 |
| Sunlight r5.2xlarge | Xeond | CentOS 7 | Enabled | 432.584 | 253.435 | 342.009 |
| Sunlight r5.2xlarge | BP | CentOS 7 | Enabled | 311.292 | 254.331 | 282.801 |
| Sunlight r5.2xlarge | Xeond | CentOS 8.3 | Disabled | 480.56 | 257.45 | 369.005 |
| Sunlight r5.2xlarge | BP | CentOS 8.3 | Disabled | 302.372 | 242.428 | 272.4 |
| Sunlight r5.2xlarge | Xeond | CentOS 8.3 | Enabled | 438.582 | 236.497 | 337.539 |
| Sunlight r5.2xlarge | BP | CentOS 8.3 | Enabled | 335.295 | 253.327 | 294.311 |
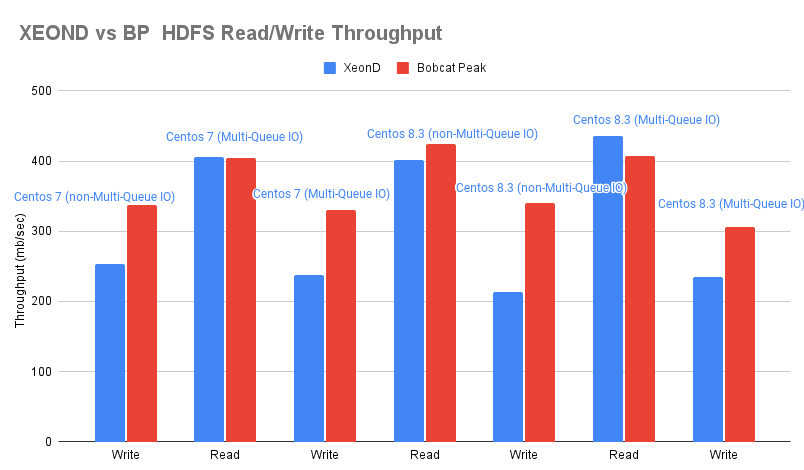
Throughput test
| Flavour | Server Enviroment | Host OS | Multi-Queue Block | Write | Read | Combined RW (50:50) |
|---|---|---|---|---|---|---|
| Sunlight r5.2xlarge | Xeond | CentOS 7 | Disabled | 253.62 | 417.74 | 335.68 |
| Sunlight r5.2xlarge | BP | CentOS 7 | Disabled | 337.08 | 421.61 | 379.345 |
| Sunlight r5.2xlarge | Xeond | CentOS 7 | Enabled | 237.4 | 405.72 | 321.56 |
| Sunlight r5.2xlarge | BP | CentOS 7 | Enabled | 330.46 | 404.91 | 367.685 |
| Sunlight r5.2xlarge | Xeond | CentOS 8.3 | Disabled | 213.58 | 400.8 | 307.19 |
| Sunlight r5.2xlarge | BP | CentOS 8.3 | Disabled | 340.65 | 424.54 | 382.595 |
| Sunlight r5.2xlarge | Xeond | CentOS 8.3 | Enabled | 234.39 | 435.96 | 335.175 |
| Sunlight r5.2xlarge | BP | CentOS 8.3 | Enabled | 306.57 | 406.73 | 356.65 |
The results between the 2 tested environments demonstrate better performance in Bobcat peak nodes rather than XeonD nodes in most cases.
Performance Evaluation Graphs